Scalable Microservice with Multiple Apache Kafka Brokers with Multiple ZooKeeper Nodes using bitnami/kafka:3.4 docker image with kafkajs node package — PART I (Introduction and motivation)

These are the things you can get to know from this article.
- Backstory of using Apache Kafka
- Why Bitunami/Kafka instead of other docker Kafka image types?
- Why I chose ZooKeeper instead of KRaft?
- Reasons for using other libraries and tools
Backstory of using Apache Kafka
Here is the backstory for this one. I did part of a event-driven microservices personal project. So I needed to communicate between the microservices. When thinking about the communication way, these things came up to my mind.
- Asynchronous Communication
- Loose Coupling
- Scalability
- Fault Tolerance
- Load Balancing
- Event Sourcing
- Data Integration
- Real-Time Analytics
- Distributed System Support
- Reliability and Durability
- Decoupled Development and Deployment
To achieve these I then came up with the normal standard way of using message brokers. Some can say “Why did you use message brockers? Instead of that you can use AWS services like SQS like that”. But I needed to go into the basics and the concepts in here also because I’m a new to this message broker concept. Then the problem was choosing between popular message brokers which we know as “Apache Kafka” and “RabbitMQ”. In there I did a comparison between them.
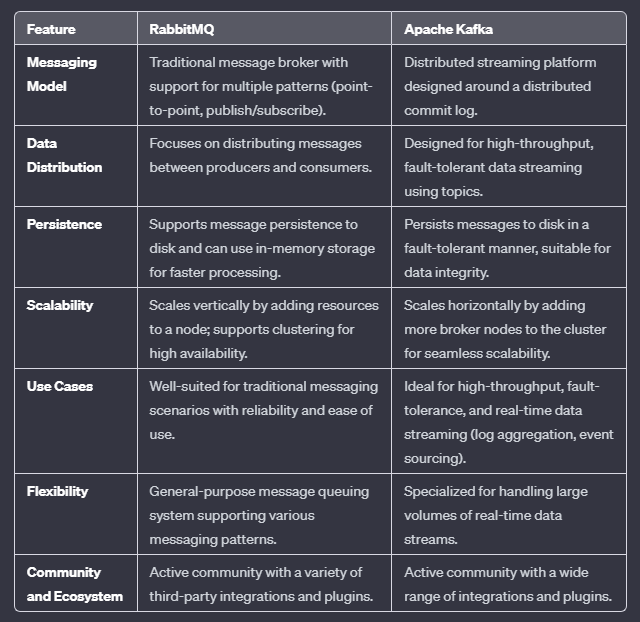
I chose Apache Kafka over RabbitMQ because I thought Kafka’s structure, with its distributed commit log, would be simpler for me to understand distributed systems. Kafka’s focus on high-throughput event streaming matched my goal of learning real-time data processing. Its scalability and parallelism features seemed better for my learning needs, making Kafka a more effective choice for understanding scalable and fault-tolerant event streaming. So I choose “Apache Kafka” as my message broker.
Why Bitunami/Kafka instead of other docker Kafka image types?
I decided to use the Bitnami/Kafka Docker image for several reasons, with one key factor being its simplicity and ease of use. Bitnami provides a well-configured and pre-packaged solution that streamlines the setup and deployment process for Kafka. This particular Docker image comes with sensible defaults, reducing the need for extensive configuration and making it accessible for users at various experience levels. Spcially the main reason is its lightweight nature. The Bitnami/Kafka image has a smaller size compared to some other alternatives. This is particularly beneficial for optimizing resource utilization and facilitating quicker image downloads, ensuring a more efficient and agile development and deployment process. Overall, I thought the combination of simplicity, user-friendliness, and a smaller footprint makes Bitnami/Kafka an appealing choice for my project.
Why I choose ZooKeeper instead of Kraft?
First lets get idea what is ZooKeeper and what is Kraft. ZooKeeper is a separate distributed system which is to,
- Determining the leader of the brokers in a given a partition and topic
- To track the Kafka clusters behaviour
- For managing partition
- To provide a distributed coordination
- To provide a synchronization service.
ZooKeeper use client server architecture to maintain and manage Kafka brokers. These are the main tasks of ZooKeeper when running with Kafka.
- Leader elections
- ZooKeeper helps Kafka brokers determine which broker is the leader of a given partition and topic. It also manages service discovery and cluster topology.
- Configuration storage
— Zookeeper stores configurations for topics and permissions. - Notification sending
— ZooKeeper sends notifications to Kafka when changes occur, such as a new topic, a broker dying, or a broker coming up. - Cluster coordination
— Zookeeper coordinates clusters, maintains metadata, tracks broker availability, and manages consumer groups. - Cluster topology management
— ZooKeeper manages cluster topology so each broker knows when brokers have entered or exited the cluster. - Kafka topic and message maintenance
— ZooKeeper tracks the status of nodes in the Kafka cluster and maintains a list of Kafka topics and messages.
So ZooKeeper and Kafka works as two separate systems and the only thing is ZooKeeper manages Kafka. In here you can see that have to deploy ZooKeeper images also if we are using this approach. But in the other end ZooKeeper reduces stress of configuring, controlling and deploying of Kafka.
Lets get a idea about Kraft. KRaft, short for Kafka Raft Metadata mode, is a major architectural shift in the Apache Kafka streaming platform, replacing the traditional dependency on Apache ZooKeeper for metadata management. In the previous Kafka architecture, ZooKeeper was utilized to maintain the metadata of the cluster. However, this introduced complexity and limitations, leading to a series of Kafka Improvement Proposals (KIPs) that resulted in the development of KRaft. KRaft employs the Raft consensus protocol, offering a self-managed metadata quorum within Kafka. This approach simplifies deployment, enhances scalability, and improves performance compared to the older ZooKeeper-based model.
KRaft operates with a quorum-based controller, adopting an event-sourced storage model and utilizing Kafka Raft for consensus on metadata management. The quorum controller functions in a leader-follower mode, where the leader generates events in the metadata topic, and follower controllers consume and apply these events. This event-driven mechanism ensures consistency and durability across the quorum. The transition to KRaft offers several benefits, including simplified architecture, improved scalability by reducing the load on the metadata store, enhanced availability with resilience to partial failures, simplified deployment without the need for a separate ZooKeeper cluster, and increased security features.
KRaft was introduced to address the limitations of ZooKeeper and to provide a more streamlined, scalable, and efficient solution for Kafka’s metadata management. The transition from ZooKeeper to KRaft involves upgrading to Kafka 2.8 or later, enabling KRaft mode, and following a specific migration procedure. With KRaft, Kafka users experience a more straightforward and unified system for managing both data and metadata, leading to an overall improvement in operational simplicity and system performance.
So the reason for choosing Kraft instead of ZooKeeper as the first approach for my project is, I wanted to experiment both methods and get hands on experience to grab the concepts of these two approaches. So as the first step I chose ZooKeeper.
Reasons for using other libraries and tools
So for this project I choose other libraries and tools because of these reasons.
- NodeJS and Express — I’m more familiarize with this.
- KafkaJS — As I saw its the most commonly used node library for Kafka.
- Docker and docker-compose-No needed to be worry of the dependencies and can isolate applications with ease.
- Bitunami/Kafka — Its a lightweight image.
See you in the PART II (Project structure and using KafkaJS)…
Please give a clap 👏🏻 if you like this article and also if its useful. Thank you :)